Telegram 的中文搜索是出了名的难用,只要涉及到中文、或者中英文混杂,就原地暴毙:
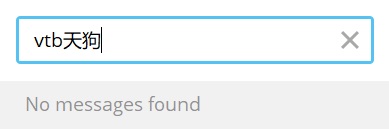
就比如遇到这种想找黑历史的时候,搜索功能摆在这里却用不了,只能原地感叹一句要你何用。忍忍总也有个限度,当我第 n 次想找历史记录但是无论如何也找不到的时候,一拍脑袋:
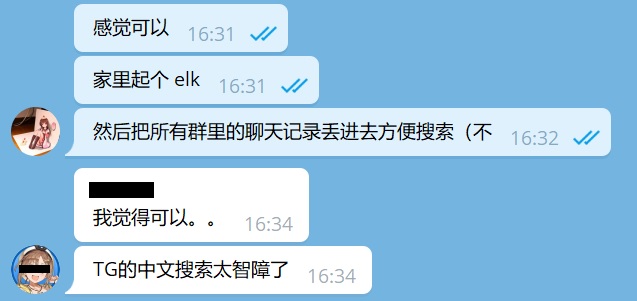
思路很简单嘛,公司里用 ELK 搜日志,聊天记录的本质就是聊天的日志,那干脆就用 ELK 来自建一个聊天记录搜索给自己用就好了嘛。这样来看,待实现的需求就只有历史数据的获取和聊天记录实时写入了。
部署一套 Elastic Stack 并不麻烦,最省事儿的途径就是直接用 docker。我这边呢继续用家里的 ESXi,开了一台独立的 VM,感觉没必要用 docker 再套一层,就稍微麻烦一点,从源里面安装 elasticsearch 和 kibana 就可以了,具体过程和配置都可以参照 Arch Wiki。
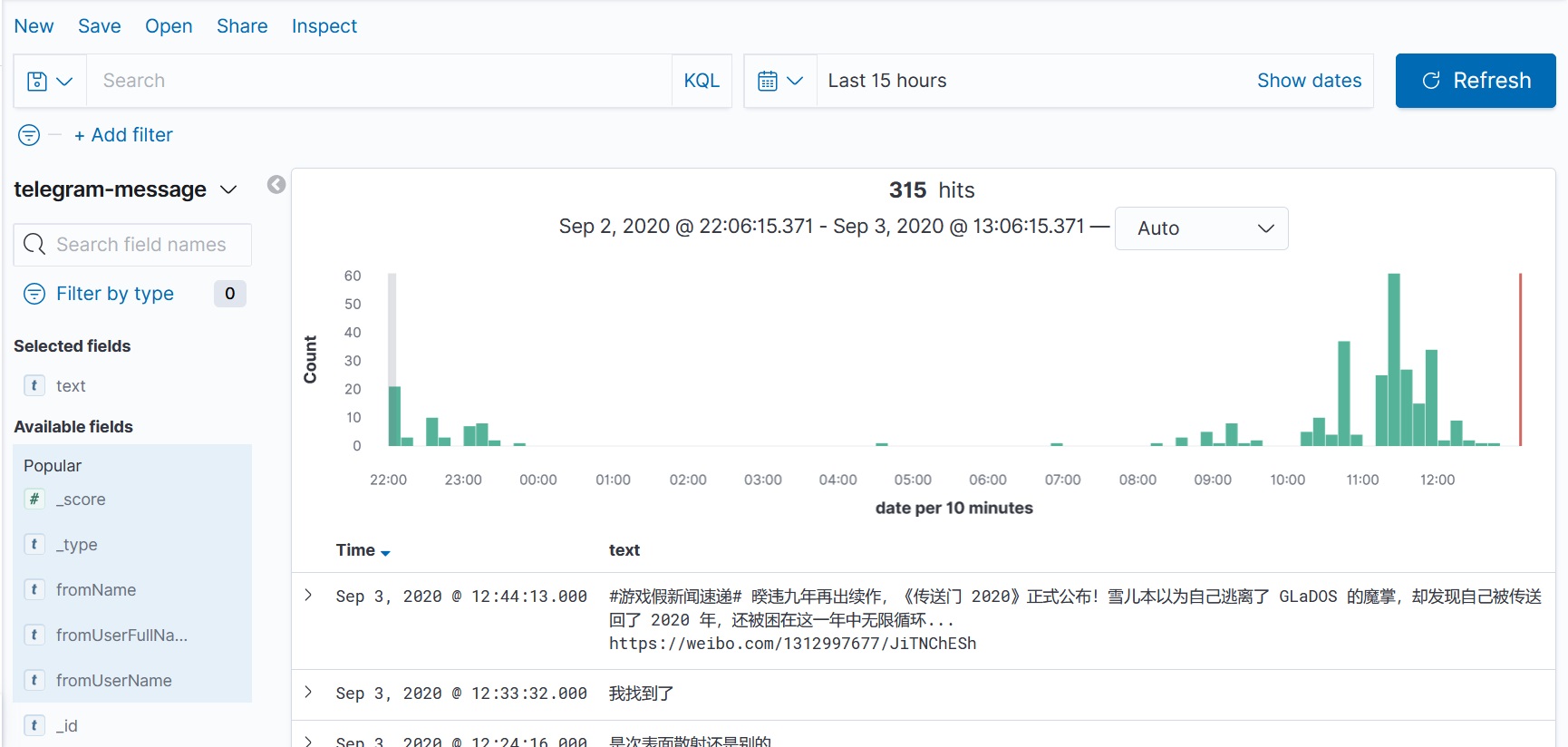
之后就是数据来源了。众所周知 Telegram 对二次开发是十分友好,所有人都可以直接用官方提供了 C++ 开发的 Telegram Database Library (TDLib) 来做一个具备完整功能的客户端。我这边具体要做的也就是获取一下会话列表,然后挑选其中几个把所有数据全都 POST 到 elastic 里就可以了。TDLib 提供了 JSON API,因此衍生出了各种语言的包装库,这里随便挑选一个顺手的,照着文档写也没什么难度。导入记录实际花销和代理质量以及水群多少有关系,我这边花了四五个小时吧。完成之后数据就可以在 Discover 中查找了:
当然利用 Kibana 提供的可视化功能,我们可以查看到很多很有趣的图表了,我随手创建了一些:
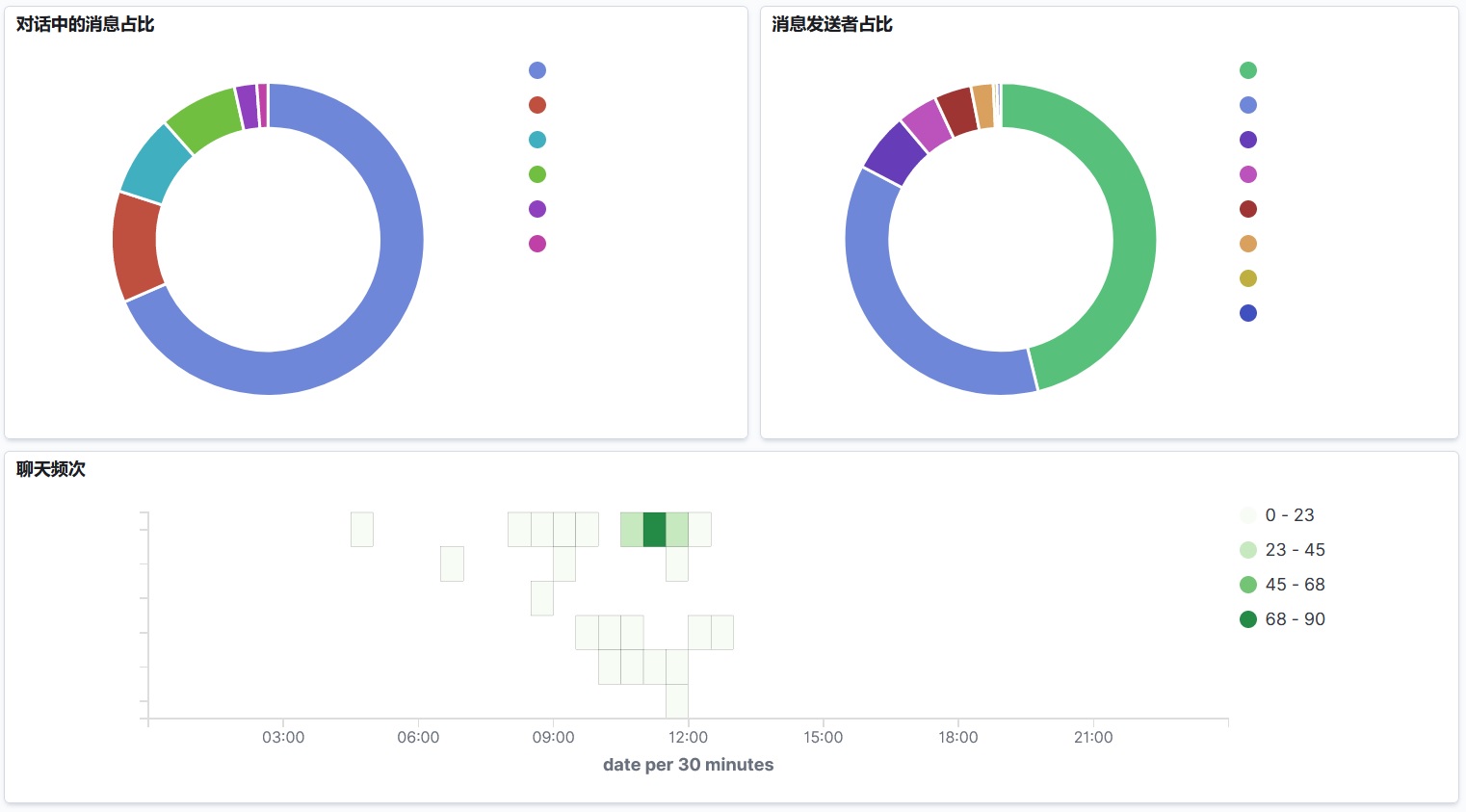
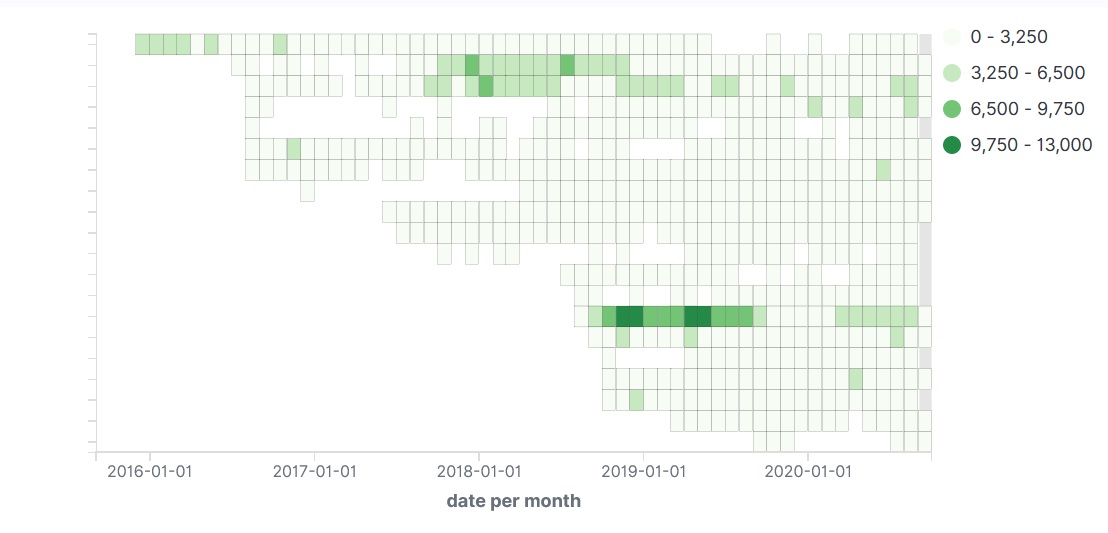
或者可以看看我关注的几个群/对话中消息在所有历史中的占比:
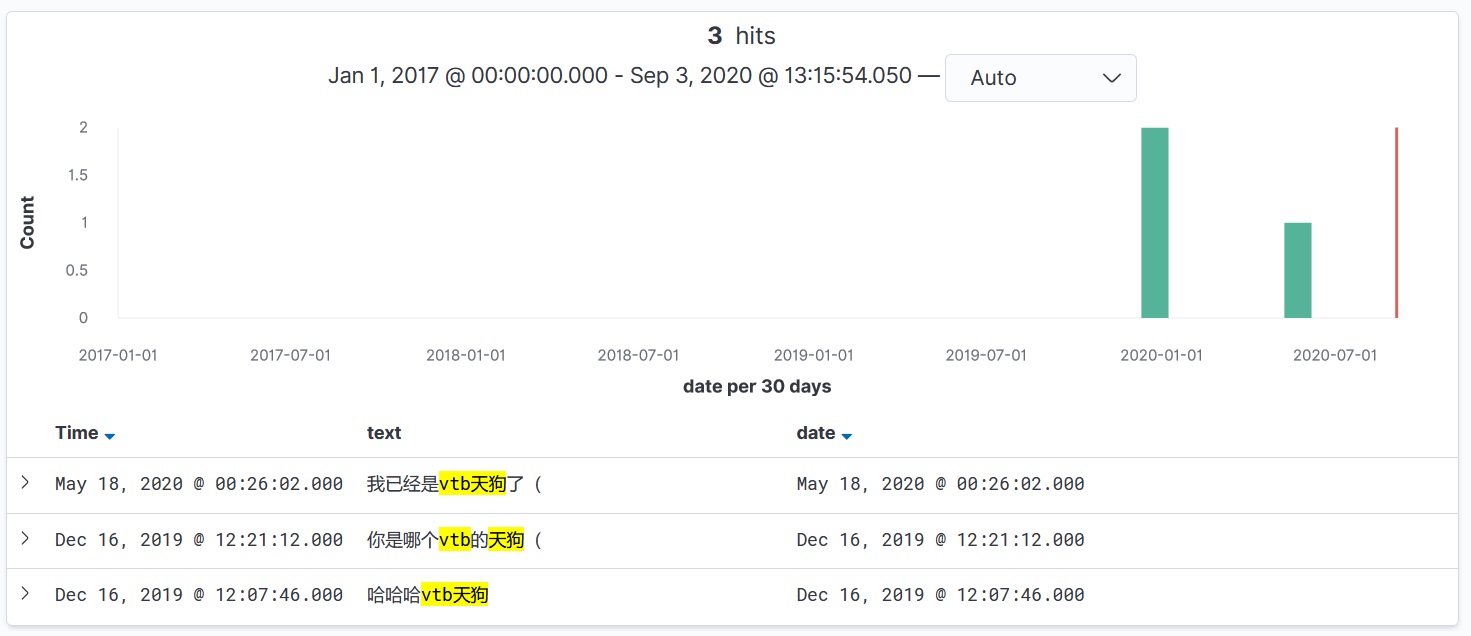
最后再回到开头的截图,咱们去 Elastic 里搜一下相同的关键字:
之后可以直接再去 Telegram 搜整句来定位上下文:
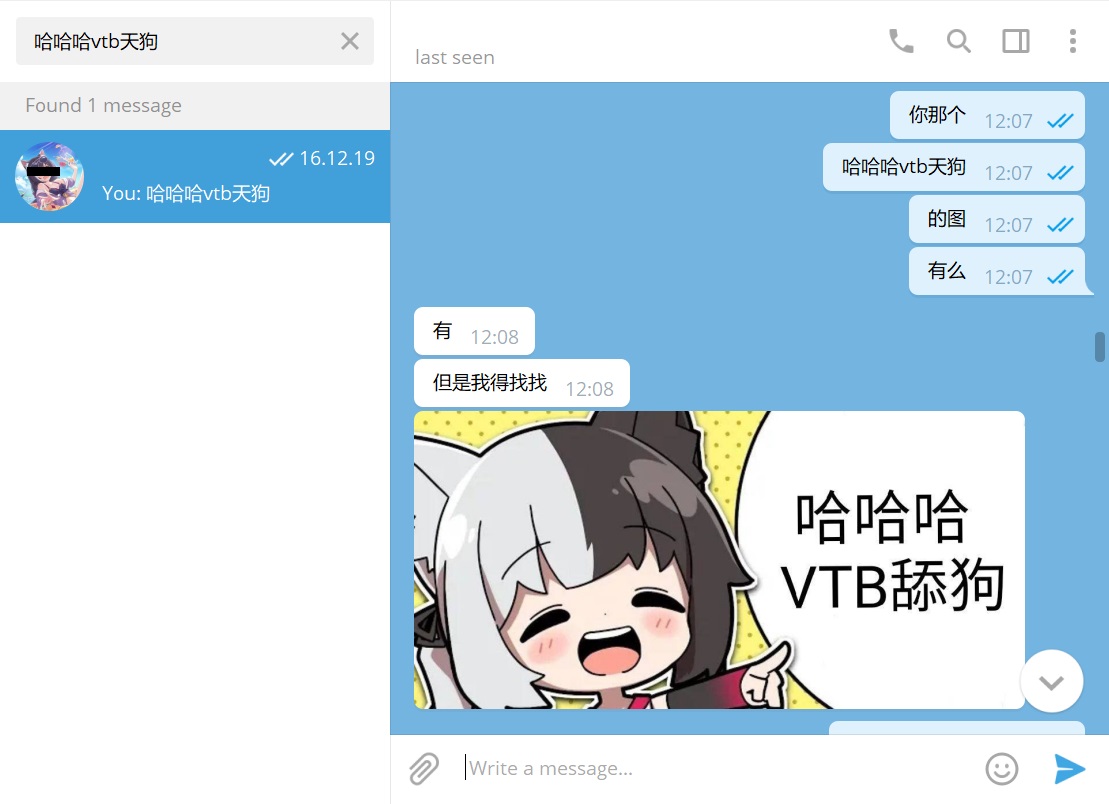
舒服了!